
Hohe Verfügbarkeit und Lastverteilung sind bei Datenbanken essenziell, aber die Umsetzung kann komplex sein. In diesem Artikel zeige ich dir, wie du ein PostgreSQL-Cluster mit Replikation und automatischem Failover einrichtest. Mit dem vorgestellten Master-Slave-Setup verbesserst du die Performance und Ausfallsicherheit deiner Anwendungen erheblich.
In diesem Artikel werden ausschließlich Open-Source-Tools aus dem PostgreSQL-Kosmos verwendet, einschließlich der aktuellen Major-Version 16 und des Community-Cluster-Managers Repmgr. Das Tutorial basiert auf Rocky Linux 9 und erklärt jede Einstellung detailliert, wodurch der Clusterbau für jeden umsetzbar ist. Dies war ein zentraler Aspekt bei der Gestaltung des Ratgebers.
Aus diesem Grund werden alle notwendigen SQL-Befehle vorgestellt. Im Laufe des Ratgebers wird unter anderem das Anlegen einer Datenbank zum Testen der Streaming-Replikation gezeigt. Du lernst außerdem, wie man Benutzer erstellt und sich generell in PSQL zurechtfindet. Denn das Kommandozeilenprogramm für PostgreSQL verfügt über viele dedizierte Befehle.
Welche Teile bilden das Cluster?
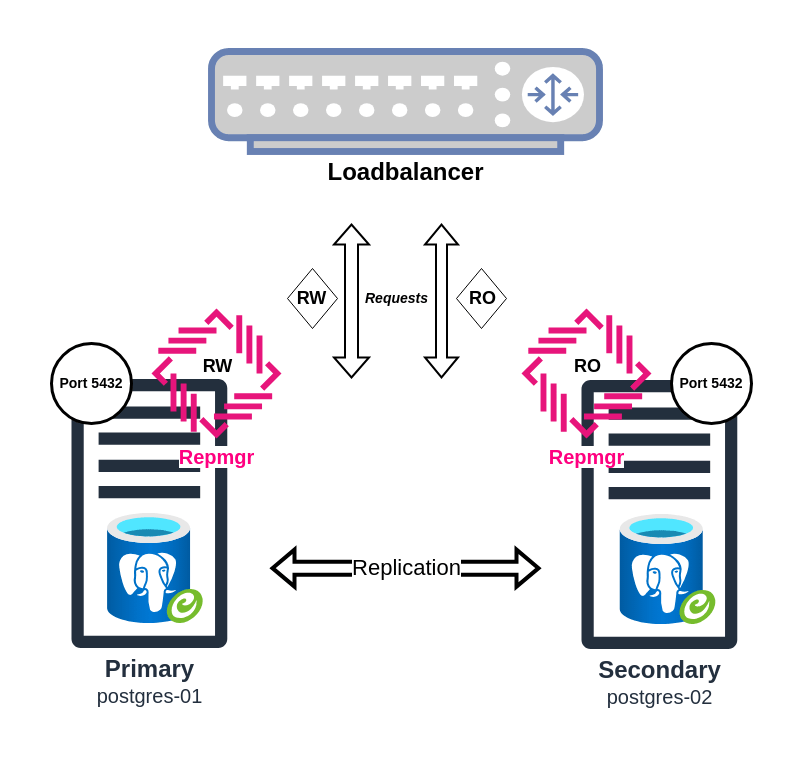
Ein primitives 2-Node-Cluster lässt sich schnell und unkompliziert mit den Bordmitteln aufbauen. Dadurch erhält man eine voll funktionsfähige Replikation vom Primärknoten zum Sekundärknoten. Der zweite Server kann zusätzlich zu seiner Rolle als Backupserver noch Read-only-Anfragen entgegennehmen, was den Primärknoten etwas entlastet.
Darüber hinaus ermöglicht diese Konfiguration die Erstellung von Dumps auf dem weniger ausgelasteten Secondary-System. Hört sich eigentlich alles recht gut an. Allerdings mangelt es dieser Standardkonfiguration an einem automatischen Failover-Mechanismus. Bei einem Ausfall des primären Servers muss der sekundäre Server nämlich von Hand zum neuen Primärserver ernannt werden.
In diesem Setup wird der eigentliche Zweck des Clusters, nämlich die kontinuierliche Verfügbarkeit der Datenbanken sicherzustellen, nicht erfüllt. Ich verwende diese simple Konfiguration in meinem Homelab, da meine beiden Server nachts für Sicherungszwecke heruntergefahren werden und so unnötige Leader-Elections vermieden werden sollen.
Wer jedoch kritische Datenbanken betreibt, sollte einen genaueren Blick auf den Replication Manager repmgr werfen. Dieses Community-Addon erweitert die Cluster-Funktionalität um den essenziellen automatischen Failover. Die Installation gestaltet sich dabei kaum schwieriger oder zeitintensiver. In den folgenden Zeilen werde ich genauer auf die jeweiligen Cluster-Bestandteile eingehen.
PostgreSQL – Datenbankmanagementsystem:
PostgreSQL ist ein leistungsstarkes relationales Datenbankmanagementsystem, das sich durch eine Vielzahl fortgeschrittener SQL-Features auszeichnet. Es arbeitet nach dem ACID-Standard, was für Atomicity (Atomarität), Consistency (Konsistenz), Isolation (Isolation) und Durability (Dauerhaftigkeit) steht. Dadurch gewährleistet PostgreSQL äußerst robuste Transaktionen.
PostgreSQL zeichnet sich durch seine Erweiterbarkeit mittels benutzerdefinierter Funktionen und Trigger aus, unterstützt JSON-Daten und bietet umfangreiche Geodatenverarbeitung. Im Vergleich zu MySQL und MariaDB, die auf Geschwindigkeit und Skalierbarkeit fokussiert sind, bietet PostgreSQL eine breitere Palette an Funktionen für komplexe Abfragen und Transaktionen.
Als Administrator für Rocky Linux sind solche Aspekte möglicherweise weniger relevant. Stattdessen solltest du die folgenden Dinge wissen:
- Binaries: Im Verzeichnis /usr/pgsql-16/bin/ befinden sich die Standardprogramme von PostgreSQL. Zusätzlich werden hier auch Erweiterungen wie repmgr hinein installiert.
- Daten: Unter /var/lib/pgsql/16/data/ findet man nicht nur die Datenbank auf Dateisystemebene, sondern auch Konfigurationsdateien.
- Postgres: Hierbei handelt es sich um den lokalen Administrator-Account, der außerdem noch vollen Zugriff auf alle Datenbanken ermöglicht. Der Ordner /var/lib/pgsql dient als Home-Verzeichnis des Superusers.
- Konfiguration: Standardmäßig werden Einstellungen, wie das Performance-Tuning oder die Replikationseinstellungen, in der Datei /var/lib/pgsql/16/data/postgresql.conf vorgenommen.
- Zugriffssteuerung: In der Datei /var/lib/pgsql/16/data/pg_hba.conf werden die Zugriffsrichtlinien für die Datenbanken konfiguriert.
Ziel dieses Artikels ist es, eine Streaming-Replikation einzurichten, die die Standardform bei PostgreSQL-Datenbanken darstellt. Dabei wird der Master-Knoten nahezu in Echtzeit auf den Sekundärknoten repliziert, mit Ausnahme der Konfigurationsdateien. Die Streaming-Replikation nutzt das Write-Ahead Logging (WAL), um Änderungen vom Master an die Sekundärknoten zu übertragen.
- Du hast es sicherlich schon bemerkt: Die Zahl 16 steht für die installierte Hauptversion von PostgreSQL. Für die Versionen 13 bis 15 müssen die Pfade entsprechend angepasst werden. Wenn der Standardpfad geändert wurde, kann die Umgebungsvariable $PGDATA ausgelesen werden oder der Pfad via systemctl cat postgresql-16.service nachgesehen werden.
Repmgr – Replication Manager CLI:
Es handelt sich hierbei um ein umfangreiches Kommandozeilen-Programm, welches du zum Management deines PostgreSQL Clusters benötigst. Du kannst mit dem Tool eine ganze Menge anstellen:
- Replikation konfigurieren, Standbys zu Primärservern befördern, Switchover für Wartungszwecke durchführen oder den Status der Replikation, des Clusters oder einzelner Nodes abfragen.
- Für praktisch jeden Befehl gibt es eine Testoption. Nutze einfach –dry-run in deinem Kommando, um einen Funktionstest durchzuführen und gegebenenfalls eine Fehlermeldung zu erhalten.
- Die Konfiguration des Replication Managers repmgr erfolgt über die Datei /etc/repmgr/16/repmgr.conf. Jede Direktive ist dort ausführlich kommentiert, was deren Konfiguration enorm erleichtert.
- Der Replication Manager muss immer entsprechend zur verwendeten PostgreSQL-Version installiert werden, da sonst Inkompatibilitäten und Datenverluste auftreten können. Die Pakete aus den offiziellen Repositories für Red Hat und seine Derivate tragen praktischerweise ein Suffix, das dem jeweiligen Release entspricht.
Repmgrd – Replication Manager Daemon:
Es handelt sich hierbei um den Hintergrundprozess des Replication Managers. Seine Hauptaufgabe besteht darin, das PostgreSQL-Cluster zu überwachen, automatisierte Verwaltungsaufgaben durchzuführen und im Falle von Ausfällen oder geplanten Wartungsarbeiten entsprechende Aktionen einzuleiten. Im Folgenden habe ich dir die wichtigsten Aufgaben aufgelistet:
- Überwachung des Cluster-Zustands: Der Daemon überwacht kontinuierlich den Zustand aller Knoten im PostgreSQL-Cluster, einschließlich des Primärknotens und der Standby-Knoten.
- Automatisches Failover: Im Falle eines Ausfalls des Primärknotens erkennt Repmgrd dies automatisch und fördert einen der Standby-Knoten zum neuen Primärknoten. Dies gewährleistet eine minimale Ausfallzeit und sorgt für eine dauerhafte Verfügbarkeit der Datenbanken.
- Switchover-Unterstützung: Für geplante Wartungsarbeiten oder Upgrades kann der repmgrd auch einen geordneten Switchover durchführen. Dabei wird ein Standby-Knoten zum neuen Primärknoten befördert, während der alte Primärknoten zum Standby-Knoten wird.
- Replikationsverwaltung: Kontinuierlich werden Daten vom Primärknoten auf die Sekundärknoten übertragen, um sicherzustellen, dass alle Standby-Knoten synchronisiert bleiben.
- Statusüberwachung und Benachrichtigungen: Der Daemon bietet eine umfassende Palette von Überwachungslösungen zum vollständigen Monitoring des Clusters. Bei bestimmten Ereignissen wie einem Failover können zudem Benachrichtigungen versendet werden.
- Protokollierung und Fehlerbehandlung: Damit Probleme schnell eingekreist und dauerhaft behoben werden können, protokolliert das Tool alle Ereignisse und getroffenen Entscheidungen.
- Ein Cluster kann auch mit drei Nodes aufgebaut werden. Der dritte Knoten muss nicht besonders leistungsfähig sein, da er nicht zwingend eine zusätzliche Datenbankreplikation hostet. Stattdessen kann er als Witness konfiguriert werden und ermöglicht damit Quorum. Dank des dritten stimmberechtigten Knotenn können Split-Brain-Situationen vermieden werden.
Wie baut man ein Cluster?

Datenbanken sind ein eigenes Fachgebiet. Es gibt viele Spezialisten in diesem Bereich, weshalb sich manche Administratoren einfach nicht an die Erstellung eines solchen Clusters herantrauen. Doch ein PostgreSQL-Cluster mit automatischem Failover ist gar nicht so schwer zu bauen oder übermäßig komplex im täglichen Betrieb.
Bevor du mit der eigentlichen Einrichtung beginnst, ist eine sorgfältige Planung unerlässlich. Hierbei solltest du folgende Punkte berücksichtigen:
- Ressourcen: Ausreichend RAM ist entscheidend für die Leistung, da er das Caching von Daten und die schnelle Ausführung von Abfragen ermöglicht. Je nach Größe der Datenbank und Komplexität der Abfragen kann die CPU-Auslastung stark variieren. Zwei Kerne und 2 GB RAM sind das absolute Minimum. Die Festplatte sollte zudem eine gute Performance bei zufälligen Lese- und Schreibzugriffen bieten.
- Netzwerk: Bei einem Cluster ist die Zuverlässigkeit der Netzwerkverbindung genauso wichtig wie die effektive Übertragungsgeschwindigkeit. Schon kleinste Verbindungsaussetzer können zu unnötigen Failover-Prozessen führen. Daher gilt als Faustregel: Verwende zwei Switches, beispielsweise in einem Stack, und nutze mindestens 1 Gbit/s schnelle Netzwerkanschlüsse.
- Backup-Strategie: Auch bei DB-Clustern ist ein regelmäßiges Backup der Systeme und ihrer Datenbanken unerlässlich. Wenn dein Backup-Server nur auf Dateiebene sichert, solltest du zusätzlich ein kleines Dump-Skript in Bash erstellen. Andernfalls besteht die Gefahr inkonsistenter Backups und es droht im Ernstfall Datenverlust.
- Unverschlüsselte Verbindungen sollten heutzutage auf jeden Fall vermieden werden. PostgreSQL ermöglicht die Verwendung von SSL-Zertifikaten, die entweder selbst signiert oder von einer anerkannten Zertifizierungsstelle ausgestellt sind. Letztere sind dabei klar vorzuziehen, da sie keine zusätzliche Client-Konfiguration erfordern.
Fundamentale Einrichtung der Nodes:
Auf beiden Rocky Linux 9 Servern solltest du einige grundlegende Einstellungen vornehmen, bevor du mit der eigentlichen Arbeit beginnst. Wenn du eine Firewall verwendest, musst du den PostgreSQL-Port 5432 freigeben. Außerdem sollte auf deinem System Rsync installiert sein. Obwohl dies nicht offiziell erforderlich ist, ermöglicht es dir, gezielte Switchover für Wartungsarbeiten durchzuführen.
Das funktioniert jedoch nur, wenn du auch einen passwortlosen SSH-Zugang einrichtest. Dieser nutzt den Benutzer postgres, der nicht nur der lokale Superuser ist, sondern auch den Replication Manager auf deinem System ausführt. Wie du all das im Detail einrichtest, habe ich in den folgenden Zeilen beschrieben:
# Öffne den PostgreSQL-Port via Firewalld:
firewall-cmd --zone=public --add-port=5432/tcp --permanent
sudo firewall-cmd --reload
# Öffne den PostgreSQL-Port via Iptables:
iptables -A INPUT -p tcp --dport 5432 -j ACCEPT
service iptables save
service iptables restart
# Rsync installieren:
dnf install -y rsync
# Erstelle passwortlose SSH-Keys, um den Standby-Host bei Wartungsarbeiten via repmgr standby switchover zum Primary befördern zu können:
su postgres -c "ssh-keygen -t rsa -b 4096 -f /var/lib/pgsql/.ssh/id_rsa"
# SSH-Pub-Key anzeigen lassen:
cat /var/lib/pgsql/.ssh/id_rsa.pub
# Generierten Pub-Key auf dem anderen Knoten hinterlgen:
vim /var/lib/pgsql/.ssh/authorized_keys
# SSH-Verbindung testen & Host-Keys akzeptieren:
su postgres && ssh postgres@postgres-02/01.db.fabianscloud.dePostgreSQL auf Rocky Linux 9 installieren:
Nun steht die Einrichtung des Datenbankmanagementsystems auf beiden Hosts an. Zuerst musst du das offizielle Repository hinzufügen, da es die aktuelle Version 16 des Datenbankmanagementsystems enthält. In diesem Zuge solltest du auch gleich ein eventuell vorhandenes PostgreSQL-Modul entfernen. Bei einer frischen Installation sollte es ein solches aber nicht geben.
DNF-Module sind eine spezielle Funktion des Paketmanagers, die es dir ermöglicht, verschiedene Versionen von Software und deren Abhängigkeiten zu verwalten und bereitzustellen. Du kannst dir das Ganze ähnlich wie mehrere Docker-Container mit unterschiedlichen PostgreSQL-Versionen auf einem einzigen System vorstellen.
Ist auch dieser Schritt erledigt, geht es an die Installation via DNF. Um beide Systeme möglichst aufgeräumt zu halten, deaktiviere ich anschließend noch die überflüssigen Repositories für die Versionen 12 bis 15. Das erfordert dann noch ein Löschen und Neubauen des Paketcaches. Die detaillierten Anweisungen für alle Arbeitsschritte findest du in den folgenden Zeilen:
# PostgreSQL-Repository hinzufügen:
dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm
# Das DNF-Modul für PostgreSQL entfernen:
dnf -qy module disable postgresql
# PostgreSQL in Version 16 installieren:
dnf install -y postgresql16-server
# PostgreSQL in den Autostart verfrachten:
systemctl enable postgresql-16
# Repositorys für ungenutzte PostgreSQL-Varianten entfernen:
yum-config-manager --disable pgdg12 pgdg13 pgdg14 pgdg15
# Paketcache löschen und neu erstellen:
dnf clean all && dnf -y makecacheDer Zeitpunkt ist jetzt gekommen, den PostgreSQL-Dienst auf dem primären Server zu starten und unmittelbar danach die Initialisierung durchzuführen. Dabei werden im Standardverzeichnis unter /var/lib/pgsql/16/ alle notwendigen Konfigurationsdateien erstellt. Zudem werden die Datenbanken postgres, template1 und template0 angelegt.
Postgres dient dabei als Datenbank, die von Benutzern, Dienstprogrammen und Drittanbieter-Anwendungen verwendet werden kann. Template1 wie auch template0 sind hingegen reine Vorlagen, die bei späteren CREATE DATABASE-Befehlen kopiert werden. Template0 sollte dabei niemals verändert werden, wohingegen in template1 weitere Objekte hinzugefügt werden können.
Darüber hinaus legt initdb das Standardgebietsschema und die Zeichensatzkodierung des Datenbankclusters fest, die in den Vorlage-Datenbanken template1 und template0 gespeichert werden. Diese Einstellungen können jedoch für jede neue Datenbank individuell festgelegt werden. Aber genug der Theorie für heute. Diese Befehle musst du auf dem Master eingeben:
# PostgreSQL-Server auf dem primären Knoten starten:
systemctl start postgresql-16
# Datenbank-Initialisierung auf dem Master durchführen:
/usr/pgsql-16/bin/postgresql-16-setup initdb
# Initialisierung auf dem Standby-Host entfernen
rm -rfv /var/lib/pgsql/16/data/*Replication Manager aufspielen:
PostgreSQL bietet mit eigenen Bordmitteln eine Replikation an, jedoch ist damit kein automatisches Failover möglich. Deshalb muss auf beiden Cluster-Knoten zusätzlich der Replication Manager installiert werden. Dabei handelt es sich um ein Open-Source-Tool, welches natürlich auch manuelle Switchover-Operationen durchführen kann. Eingerichtet wird das Ganze wie folgt:
# Repmgr für PostgreSQL Version 16 installieren:
dnf -y install repmgr_16
# Den Replication-Manager in den Autostart packen:
systemctl enable repmgr-16.service
# Den Programmsuchpfad mithilfe der Datei .bash_profile erweitern:
su postgres
vi var/lib/pgsql/.bash_profile
# Extended path for psql binaries
export PATH=\$PATH:/usr/pgsql-16/bin
# Bearbeitete Datei .bash_profile einlesen:
source /var/lib/pgsql/.bash_profile Direkt nach der Installation werden die ersten SQL-Befehle auf dem primären Cluster-Knoten ausgeführt. Repmgr benötigt nämlich einen SQL-Benutzer samt Datenbank, in der alle notwendigen Details für das Tool selbst gespeichert werden. Zudem muss der Standardsuchpfad für den angelegten Benutzer auf die Schemas repmgr und public umgestellt werden.
Das mag für Einsteiger zunächst kompliziert klingen, ist aber alles kein Hexenwerk. Auf dem Server muss man lediglich zum Benutzer postgres werden und dann die PSQL-Shell öffnen. Das Vorgehen ist dann wie folgt:
# Öffne eine PostgreSQL-Datenbank-Sitzung als Benutzer postgres:
sudo -u postgres psql
# Lege den User repmgr an, mit einem verschlüsselten Passwort & Superuser-Rechten:
CREATE USER repmgr LOGIN CONNECTION LIMIT 3 ENCRYPTED PASSWORD 'Pa$$w0rd' SUPERUSER;
# Erstelle die Datenbank repmgr mit dem gleichnamigen Eigentümer:
CREATE DATABASE repmgr OWNER repmgr;
# Setze den Standardsuchpfad für den Benutzer repmgr auf die Schemas repmgr und public:
ALTER USER repmgr SET search_path TO repmgr, public;
# PSQL-Shell verlassen
\qPostgreSQL & Repmgr konfigurieren:
Nun wollen wir die grundlegende Konfiguration von PostgreSQL auf dem zukünftigen Primary-Server vornehmen. Im Konfigurationsfile müssen nur wenige Direktiven hinzugefügt werden. Dabei ist es wichtig, auf einige Dinge zu achten. Zum Beispiel muss der spätere Server nicht zwingend auf allen Netzwerkschnittstellen lauschen.
Außerdem ist es nicht erforderlich, dass der Secondary-Server Leseanfragen entgegennimmt. Betrachte die folgende Konfiguration daher als einen groben Vorschlag, der noch etwas Feinschliff benötigt:
# PostgreSQL-Konfiguration anpassen:
vim /var/lib/pgsql/16/data/postgresql.conf
# IP-Adressen auf die der PostgreSQL-Service lauscht:
listen_addresses = '*'
# Mindestens einen WAL-Sender mehr als es Secondary-Server im Cluster gibt:
max_wal_senders = 2
# Mindestns ein Slot mehr als es Standby-Hosts im Cluster gibt:
max_replication_slots = 2
# Jeder Secondary-Server nimmt Lese-Anfragen entgegen:
hot_standby = on
# Bessere Konsistenz und Zuverlässigkeit der Replikation:
wal_log_hints = on
# Aktivierung der WAL-Dateiarchivierung:
archive_mode = on
# Befehl zur Ablage der WAL-Files:
archive_command = 'test ! -f /var/lib/pgsql/16/data/archive/%f && cp %p /mnt/server/archivedir/%f'Damit ist es aber noch nicht ganz getan. Bei PostgreSQL gibt es noch eine weitere wichtige Konfigurationsdatei, nämlich die pg_hba.conf. In diesem File wird gesteuert, welcher Benutzer woher auf den Datenbank-Server zugreifen darf. In unserem Fall betrifft das den durch uns angelegten Benutzer repmgr mit der gleichnamigen Datenbank.
Außerdem benötigt der Benutzer Zugriff auf die von PostgreSQL selbst erstellte Datenbank replication. Hier ist der Name Programm. Gespeichert werden dort wichtige Details zur Replikation. Letztlich musst du nur die folgenden Zeilen ans Ende der Konfigurationsdatei kopieren. Bitte denke daran, die IP-Adressen entsprechend denen deiner Cluster-Knoten anzupassen:
# Zugriffssteuerung für die replikationsrelevanten Datenbanken hinzufügen:
vim /var/lib/pgsql/16/data/pg_hba.conf
# Datenbank replication für user repmgr
local replication repmgr trust
host replication repmgr 127.0.0.1/32 md5
host replication repmgr 10.10.10.231/32 md5
host replication repmgr 10.10.10.232/32 md5
# Datenbank repmgr für user repmgr
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 md5
host repmgr repmgr 10.10.10.231/32 md5
host repmgr repmgr 10.10.10.232/32 md5Das Passwort für den Benutzer repmgr kann in der Konfiguration des Replication Manager hineinschreiben. Sinnvoll ist das aber nicht. Es lässt sich dann recht einfach in der PSQL-CLI auslesen. Eine elegantere Variante ist die Nutzung von .pgpass, einer versteckten Datei, die Passwörter für diverse Zugriffskonstellationen speichert. Folgende Schritte musst du auf dem primären Server ausführen:
# Zum Linux-User postgres werden, der den Repmgr-Prozess ausführt:
su postgres
# Passwort-Datei .pgpass erstellen, damit sich der Nutzer postgres als User repmgr beim DB-Server anmelden kann:
cat << EOF > ~/.pgpass
localhost:5432:*:repmgr:Pa\$\$w0rd
127.0.0.1:5432:*:repmgr:Pa\$\$w0rd
postgres-01.db.fabianscloud.de:5432:*:repmgr:Pa\$\$w0rd
postgres-02.db.fabianscloud.de:5432:*:repmgr:Pa\$\$w0rd
EOF
# Berechtigungen anpassen:
chmod 600 ~/.pgpass
# Verbindung mit dem .pgpass-File auf dem Primary prüfen:
sudo -u postgres psql -h localhost -U repmgr -d repmgrNun müssen wir noch die Konfiguration des Replication Managers auf dem primären Server durchführen. Die Konfiguration dafür findest du im Folgenden. Denke daran, den Hostnamen deines lokalen Systems korrekt in der Conninfo-Direktive einzutragen. Andernfalls wird die Registrierung des primären Hosts im Cluster nicht funktionieren.
vim /etc/repmgr/16/repmgr.conf
# 1 ist standardmäßig der primäre Knoten:
node_id=1
# FQDN des lokalen Systems:
node_name='postgres-01.db.fabianscloud.de'
# Das Passwort wird aus der Datei /var/lib/pgsql/.pgpass ausgelesen:
conninfo='host=postgres-01.db.fabianscloud.de port=5432 user=repmgr dbname=repmgr connect_timeout=2'
# Ort, wo sich das Passwortfile für die Conninfo befindet:
passfile='/var/lib/pgsql/.pgpass'
# Pfad zum Datenverzeichnis der PostgreSQL-Installation:
data_directory='/var/lib/pgsql/16/data/'
# WAL-Dateien so lange aufbewahrt werden, bis alle Replikationsprozesse sie erfolgreich verarbeitet haben:
use_replication_slots=true
# Alle Logeinträge ab dem Warnungslevel werden nach /var/log/messages geschrieben:
log_level='WARNING'
# Aktivierung des automatischen Failovers:
failover='automatic'
# Kommando, um den Primary-Server zu bestimmen:
promote_command='/usr/pgsql-16/bin/repmgr standby promote -f /etc/repmgr/16/repmgr.conf --log-to-file'
# Dieser Befehl definiert, wie ein Standby-Server einem neuen Primärserver folgen soll:
follow_command='/usr/pgsql-16/bin/repmgr standby follow -f /etc/repmgr/16/repmgr.conf --log-to-file --upstream-node-id=%n'
# Alle 2 Sekunden wird der Cluster-Status geprüft:
monitor_interval_secs=2
# PQping() prüft, ob der PostgreSQL-Node Verbindungen akzeptiert:
connection_check_type='ping'
# Maximale Anzahl an Verbindungsversuchen:
reconnect_attempts=6
# Intervall zwischen den Verbindungsversuchen:
reconnect_interval=10
# Standby-Knoten trennen bei einem Master-Ausfall sofort ihre WAL-Verbindung. Dies führt zu einer schnelleren Failover-Geschwindigkeit und reduziert Konflikte sowie daraus resultierende Inkonsistenzen:
standby_disconnect_on_failover=true
# PostgreSQL-Kommando fürs Starten:
service_start_command = 'sudo systemctl start postgresql-16'
# PostgreSQL-Kommando fürs Stoppen:
service_stop_command = 'sudo systemctl stop postgresql-16'
# PostgreSQL-Kommando fürs Neustarten:
service_restart_command = 'sudo systemctl restart postgresql-16'
# PostgreSQL-Kommando fürs Konfiguration laden:
service_reload_command = 'sudo systemctl reload postgresql-16'Wie du bereits bemerkt haben solltest, nutzt die obige Konfiguration Systemd zur Steuerung der PostgreSQL-Instanz. Da der Repmgr-Prozess durch den auf dem Linux-System unprivilegierten User postgres ausgeführt wird, muss dieser noch mit Sudo-Rechten für das Service-Handling ausgestattet werden. Dies lässt sich im Handumdrehen mit den folgenden Arbeitsschritten bewerkstelligen:
# Sudoers-File für den User postgres erstellen:
visudo /etc/sudoers.d/repmgr-postgres
Defaults:postgres !requiretty
postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-16, \
/usr/bin/systemctl start postgresql-16, \
/usr/bin/systemctl restart postgresql-16, \
/usr/bin/systemctl reload postgresql-16
# Syntax der Sudoers-Datei prüfen:
visudo -c /etc/sudoers.d/repmgr-postgresJetzt ist der Zeitpunkt gekommen, an dem das Cluster endlich erstellt werden kann. Dazu muss der PostgreSQL-Dienst auf dem Master-Knoten aber noch neu gestartet werden, damit die Konfiguration korrekt übernommen wird. Danach kann der primäre Knoten in das Datenbank-Cluster aufgenommen werden. Eine Anleitung dazu findest du hier:
# PostgreSQL-Konfiguration erneut einlesen:
systemctl restart postgresql-16.service
# Erstelle das Cluster, indem der primäre Node registriert wird:
su postgres -c "repmgr -f /etc/repmgr/16/repmgr.conf primary register" Im Optimalfall erscheint dabei keine Fehlermeldung in der Konsole, und du kannst dein zur Hälfte fertiges Cluster bestaunen. Dies gelingt dir mithilfe des folgenden Kommandos:
# Prüfe, ob die Registrierung erfolgreich war und Cluster steht:
su postgres -c "repmgr -f /etc/repmgr/16/repmgr.conf cluster show"
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+--------------------------------------+---------+-----------+----------+----------+----------+----------+-------------------------------------------------------------------------------------------------
1 | postgres-01.db.fabianscloud.de | primary | * running | | default | 100 | 1 | host=postgres-01.db.fabianscloud.de port=5432 user=repmgr dbname=repmgr connect_timeout=2
Nun fehlt nur noch der zweite Host im Cluster. Dafür müssen jedoch noch einige Arbeitsschritte durchgeführt werden, wie die Einrichtung des Cluster-Managers und das Spiegeln der Daten. Wir beginnen mit dem Replication Manager, dessen Konfiguration ähnlich wie die des Primary ist. Lediglich die Node-ID ist hier 2 und in der Conninfo-Direktive steht der Hostname des Secondary geschrieben:
vim /etc/repmgr/16/repmgr.conf
# Zweiter Cluster-Node erhält die ID 2:
node_id=2
# FQDN des lokalen Systems:
node_name='postgres-02.db.fabianscloud.de'
# Das Passwort wird aus der Datei /var/lib/pgsql/.pgpass ausgelesen:
conninfo='host=postgres-02.db.fabianscloud.de port=5432 user=repmgr dbname=repmgr connect_timeout=2'
# Ort, wo sich das Passwortfile für die Conninfo befindet:
passfile='/var/lib/pgsql/.pgpass'
# Pfad zum Datenverzeichnis der PostgreSQL-Installation:
data_directory='/var/lib/pgsql/16/data/'
# WAL-Dateien so lange aufbewahrt werden, bis alle Replikationsprozesse sie erfolgreich verarbeitet haben:
use_replication_slots=true
# Alle Logeinträge ab dem Warnungslevel werden nach /var/log/messages geschrieben:
log_level='WARNING'
# Aktivierung des automatischen Failovers:
failover='automatic'
# Kommando, um den Primary-Server zu bestimmen:
promote_command='/usr/pgsql-16/bin/repmgr standby promote -f /etc/repmgr/16/repmgr.conf --log-to-file'
# Dieser Befehl definiert, wie ein Standby-Server einem neuen Primärserver folgen soll:
follow_command='/usr/pgsql-16/bin/repmgr standby follow -f /etc/repmgr/16/repmgr.conf --log-to-file --upstream-node-id=%n'
# Alle 2 Sekunden wird der Cluster-Status geprüft:
monitor_interval_secs=2
# PQping() prüft, ob der PostgreSQL-Node Verbindungen akzeptiert:
connection_check_type='ping'
# Maximale Anzahl an Verbindungsversuchen:
reconnect_attempts=6
# Intervall zwischen den Verbindungsversuchen:
reconnect_interval=10
# Standby-Knoten trennen bei einem Master-Ausfall sofort ihre WAL-Verbindung. Dies führt zu einer schnelleren Failover-Geschwindigkeit und reduziert Konflikte sowie daraus resultierende Inkonsistenzen:
standby_disconnect_on_failover=true
# PostgreSQL-Kommando fürs Starten:
service_start_command = 'sudo systemctl start postgresql-16'
# PostgreSQL-Kommando fürs Stoppen:
service_stop_command = 'sudo systemctl stop postgresql-16'
# PostgreSQL-Kommando fürs Neustarten:
service_restart_command = 'sudo systemctl restart postgresql-16'
# PostgreSQL-Kommando fürs Konfiguration laden:
service_reload_command = 'sudo systemctl reload postgresql-16'Die Einrichtung von Sudo für den Benutzer postgres, damit dieser im Fehlerfall den PostgreSQL-Service neu starten kann, ist bereits abgeschlossen. Nun müssen nur noch die Daten von Primary auf den Secondary kopiert werden. Direkt im Anschluss der PostgreSQL-Dienst in den Autostart gepackt und gestartet. Nun muss man den Standby-Server nur noch im Cluster aufnehmen:
# Überprüfe, ob eine Kopie des Datenverzeichnisses vom primären Node erstellt werden kann:
su postgres -c "repmgr -h postgres-01.db.fabianscloud.de -U repmgr -d repmgr -f /etc/repmgr/16/repmgr.conf standby clone --dry-run"
# Kopiere das Datenverzeichnisses vom primären Node:
su postgres -c "repmgr -h postgres-01.db.fabianscloud.de -U repmgr -d repmgr -f /etc/repmgr/16/repmgr.conf standby clone"
# Starte den PostgreSQL-Server und packe ihn in den Autostart:
systemctl enable --now postgresql-16.service
# Füge den Node zum Cluster als Standby / Secondary hinzu:
su postgres -c "repmgr -f /etc/repmgr/16/repmgr.conf standby register"Wenn alles funktioniert hat, kannst du den Zustand deines Clusters mit dem im Folgenden vorgestellten Befehl überprüfen. Dabei sollten beide Hosts im Output erscheinen und das jeweils mit ihrer Rolle und dem Status:
# Prüfe, ob die Registrierung des Standby-Hosts erfolgreich war und Cluster steht:
su postgres -c "repmgr -f /etc/repmgr/16/repmgr.conf cluster show"
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+--------------------------------------+---------+-----------+--------------------------------------+----------+----------+----------+-------------------------------------------------------------------------------------------------
1 | postgres-01.db.fabianscloud.de | primary | * running | | default | 100 | 1 | host=postgres-01.db.fabianscloud.de port=5432 user=repmgr dbname=repmgr connect_timeout=2
2 | postgres-02.db.fabianscloud.de | standby | running | postgres-01.db.fabianscloud.de | default | 100 | 1 | host=postgres-02.db.fabianscloud.de port=5432 user=repmgr dbname=repmgr connect_timeout=2
Vertrauen ist gut, aber Kontrolle ist besser. Daher solltest du die Replikation zum Abschluss noch kurz testen. Lege dafür eine Datenbank namens test an und überprüfe anschließend auf dem Sekundär-System, ob sie dort vorhanden ist. Beachte bitte, dass du eine Datenbank nur auf dem Primary-Host erstellen kannst, da der Standby-Server maximal lesende Anfragen verarbeiten kann.
# Öffne eine PostgreSQL-Datenbank-Sitzung auf dem Primary-Knoten:
sudo -u postgres psql
# Datenbank auf dem Master-Server erstellen:
CREATE DATABASE test;
# Datenbanken auf der primären Instanz anzeigen lassen:
\l
# Öffne eine PostgreSQL-Datenbank-Sitzung auf dem Secondary-Knoten:
sudo -u postgres psql
# Datenbanken auf dem sekundären Knoten anzeigen lassen:
\l
# Datenbank auf dem Primary-System löschen:
DROP DATABASE test;
# Psql-CLI auf beiden Systemen verlassen:
\qProbleme erkennen und lösen:
Nicht immer läuft alles reibungslos ab. Und dann ist guter Rat teuer. Obwohl ich das Vorgehen im Artikel gründlich überprüft habe, können Bugs oder Änderungen immer auftreten. Deshalb möchte ich dir hier noch ein paar Troubleshooting-Kommandos mitgeben. Mit diesen solltest du die häufigsten Fehlerquellen identifizieren und beheben können:
# Log-Dateien:
/var/lib/pgsql/16/data/log/
# Cluster-Events auf Auffälligkeiten untersuchen:
su postgres -c "repmgr -f /etc/repmgr/16/repmgr.conf cluster event"
# Konnetivität zwischen den Cluster-Nodes überprüfen:
su postgres -c "psql -U repmgr -h postgres-01.db.fabianscloud.de -p 5432 -d repmgr"
su postgres -c "psql -U repmgr -h postgres-02.db.fabianscloud.de -p 5432 -d replication"
# Zeige Basis-Informationen und den Replikationsstatus des lokalen Nodes an:
su postgres -c "repmgr -f /etc/repmgr/16/repmgr.conf node status"
# Führt aus Replikationssicht einige Prüfungen für den Knoten durch:
su postgres -c "repmgr -f /etc/repmgr/16/repmgr.conf node check"Diese obigen Befehle geben zuverlässig Aufschluss darüber, warum das Cluster nicht ordnungsgemäß funktioniert. Eine gründliche Diagnose und Analyse der Logs sowie der Konfigurationseinstellungen sind häufig erforderlich, um dem Problemverursacher auf die Schliche zu kommen. Oft liegt es aber einfach an unterschiedlichen PostgreSQL- oder Repmgr-Versionen auf den beiden Nodes.
Nicht selten steht ein falsches Passwort in der Datei .pgpass oder der Hostnamen in der Conninfo-Direktive des Replication Managers wurde noch nicht angepasst. Darüber hinaus kann die obige Konfiguration nach dem Einspielen eines großen Datenbank-Dumps in die Knie gehen oder recht langsam werden. Dann sollte man dem PostgreSQL-Dienst mehr Arbeitsspeicher zuteilen.
- Der Replication Manager repmgr synchronisiert nicht automatisch die Konfigurationsdateien auf die Standby-Server des Clusters. Änderungen an der Konfiguration müssen manuell auf jedem Node vorgenommen werden und der Postgre-SQL-Dienst muss im Anschluss noch neu gestartet werden. Ein einfacher Reload hat bei meinen Tests nicht immer funktioniert.