
Heutzutage gibt es kaum eine Website, die ohne die Magie eines Reverse-Proxys auskommt. Ob du es weißt oder nicht, du interagierst wahrscheinlich täglich mit ihnen, ohne das überhaupt zu bemerken. Aber keine Sorge, in diesem Artikel werde ich dir zeigen, wie du mithilfe von Nginx in wenigen Minuten einen Reverse-Proxy baust.
Egal, ob du mehrere Webserver verwalten, die Sicherheit erhöhen oder die Leistung deiner Website steigern möchtest, Nginx ist dafür das Werkzeug meiner Wahl. Und genau deshalb habe ich mich dazu entschieden, diesen umfangreichen Ratgeber zu verfassen. Im Folgenden werde ich dir zeigen, wie du die Geschwindigkeit, Zuverlässigkeit und Skalierbarkeit deiner Website steigerst.
Dies gelingt dir, indem du den Datenverkehr auf mehrere Server verteilst und Caching sowie andere Optimierungstechniken implementierst. Schritt für Schritt werde ich in diesem Beitrag durch die Installation und Konfiguration begleiten und dich hoffentlich für den Einsatz von Nginx begeistern können. Aber genug um den heißen Brei geredet, lass uns endlich loslegen.
Was Reverse-Proxys alles können:
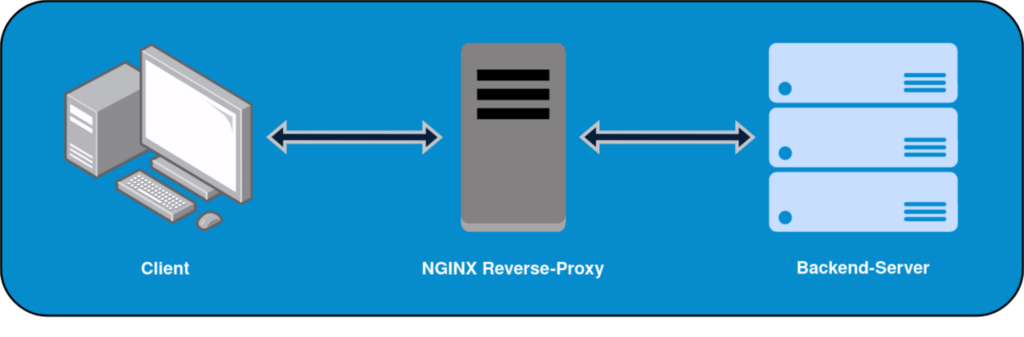
Ein Reverse-Proxy übernimmt das Entgegennehmen und Beantworten von HTTP-Anfragen, indem er diese anhand des Domainnamen an bestimmte Webserver weiterleitet. Gearbeitet wird damit also auf Layer 7 des bekannten ISO/OSI-Referenzmodells. In der Regel kümmert sich ein Reverse-Proxy auch noch um die SSL-Terminierung. Außerdem wird in der Praxis fast immer ein Pärchen betrieben.
Denn Hochverfügbarkeit wäre anders nicht umsetzbar. Doch das ist längst nicht alles, was man über Reverse-Proxys wissen sollte. Deren Einsatz kommt nämlich mit einigen höchst interessanten Vorteilen einher. Welche das genau sind und wo man sie bestmöglich einsetzen kannst, erfährst du in den folgenden Zeilen:
Loadbalancing – Verteile die Last:
Betreibt man eine Homepage auf mehreren Webservern parallel, müssen die Client-Anfragen sinnvoll zwischen den ganzen Servern verteilt werden. Dafür gibt es verschiedene Lastverteilungsalgorithmen, die ihre eigenen Vor- als auch Nachteile mit sich bringen. Hauptziel ist aber stets, dass kein Backend-Server überlastet wird und der Ausfall eines Webservers abgefangen werden kann.
Kommt es zu so einem Fall, wird der entsprechende Server einfach nicht mehr kontaktiert. Man kann also verschiedene Arten von Gesundheitschecks in Nginx konfigurieren. Davon abgesehen, lässt sich zu jeder Zeit ein weiterer Webserver in Betrieb nehmen und mit Anfragen versorgen. In puncto horizontaler Skalierbarkeit sind Reverse-Proxys also ein Must-have.
Security – Schütze deine Webserver:

Ein großer Vorteil beim Einsatz von Reverse-Proxys ist die Anonymität deiner Webserver. Das gilt zumindest dann, wenn Network-Adresse-Translation (NAT) zur Anwendung kommt. Damit kommunizieren sowohl stinknormale Clients als auch Angreifer ausschließlich mit dem vorgeschalteten Reverse-Proxy. Die IP-Adresse der im Backend befindlichen Webserver bleibt also geheim.
Damit können Hacker die Server nicht binnen weniger Minuten auskundschaften und das Einschleusen von Schadcode fällt deutlich schwerer. Im alltäglichen Betrieb ist das bereits ein gigantischer Vorteil. Allerdings ist das längst nicht der einzige positive Aspekt. So kann man die Webserver in größeren Abständen patchen und muss bei Sicherheitslücken nicht umgehend aktiv werden.
Management – Logs & Zertifikate an einem Ort:
Einfache Administration und zentrales Management sind keine unnützen Buzzwords, sondern die Schlüsseleigenschaften schön von der Hand gehender Arbeit. Da ein Reverse-Proxy den einzigen Zugriffspunkt für die Außenwelt darstellt, kann man genau hier alle SSL-Zertifikate verwalten. Darüber hinaus lässt sich an dieser Stelle loggen, welcher Traffic rein und herausgeht.
Damit eigenen sich Reverse-Proxys bestens für den Betrieb von Web Application Firewalls (WAF). Angriffe wie SQL Injections, Cross-Site Scripting (XSS) und andere Sicherheitsbedrohungen werden damit erkannt und umgehend blockiert. Da Reverse-Proxys der Mittelpunkt der Kommunikation sind, fungieren sie häufig noch als Zwischenspeicher für statische Inhalte wie Bilder, CSS und HTML.
So wird die Last der Backend-Server verringert und die Performance der Applikation spürbar verbessert. Natürlich gibt es noch viele weitere Dinge, die man mit Reverse-Proxys umsetzen kann. Allerdings würde deren Erklärung den Rahmen des Beitrags sprengen und vom eigentlichen Thema ablenken. Daher gehe ich nun endlich auf die Erstellung eines Reverse-Proxys mit Nginx ein.
Nginx-Reverse-Proxy erstellen:
Im Rahmen dieses Artikels werden wir einen simplen Reverse-Proxy mithilfe von Nginx erstellen. Ich habe zum Testen der Konfiguration ein Rocky Linux 9 System genutzt. Ich werde im Folgenden aber auch die Installationsbefehle für Debian und dessen Derivate auflisten. Dort sollte die Konfiguration nämlich ebenfalls einwandfrei funktionieren.
Ziel der heutigen Übung ist das Erstellen eines einzelnen Nginx-Reverse-Proxys. Solltest du hingegen ein hochverfügbares Setup benötigen, kannst du zum Beispiel 2 Server aufsetzen und Keepalived installieren. Damit bekommst du Hochverfügbarkeit samt Überwachung, ob der Nginx-Prozesse korrekt läuft. Du kannst dich außerdem per E-Mail benachrichtigen lassen, wenn ein Node ausfällt.
Nginx auf RedHat & Debian installieren:
Seit einigen Jahren ist Nginx in allen Standard-Paketquellen der großen Linux-Distributionen enthalten. Man kann allerdings auch das offizielle Reposiory einbinden, um schneller an Updates zu kommen. Für einen einfachen Reverse-Proxy ist das aber nicht notwendig. Die Installation geht schnell von der Hand, indem du diese Befehle im Terminal eingibst:
# Installation in RedHat:
dnf install -y nginx
# Installation in Debian:
apt-get update
apt-get install nginxAb Version 8 ist bei RedHat und dessen Derivaten Firewalld vorinstalliert und auch gleich noch im Autostart hinterlegt. Die Konfiguration geht zum Glück flott von der Hand. Du brauchst lediglich diese 3 Befehle:
# Firewalld auf RedHat-Systemen korrekt konfigurieren:
firewall-cmd --zone=public --permanent --add-service=http
firewall-cmd --zone=public --permanent --add-service=https
firewall-cmd --reloadIm Debian-Universum wird noch immer keine Firewall mitgeliefert. Ich setze daher sehr gerne auf iptables oder die einfachere Lösung ufw. Wie man die erstgenannte Variante in Betrieb nimmt, habe ich im Folgenden beschrieben:
# Iptables in Debian einsetzen:
apt-get install -y iptables
iptables -A INPUT -p tcp --dport 80 -j ACCEPT
iptables -A INPUT -p tcp --dport 443 -j ACCEPT
iptables-save > /etc/iptables/rules.v4
systemctl enable --now iptablesGrundlegende Konfiguration vornehmen:
Direkt nach der Installation entferne ich die standardmäßig hinterlegte Virtual Host Konfiguration und aktiviere den Autostart für Nginx. Gemacht wird das Ganze so:
# Default Virtual Host unter Debian deaktivieren:
unlink /etc/nginx/sites-enabled/default
# Autostart aktivieren & Dient direkt starten:
systemctl enable --now nginxNun kann es auch schon an die Konfiguration des Nginx-Reverse-Proxys gehen:
# Erstellen einer leeren Konfigurations-Datei für Debian:
touch /etc/nginx/sites-available/reverse-proxy.conf
# Erstellen einer leeren Konfigurations-Datei für RedHat:
touch /etc/nginx/conf.d/reverse-proxy.conf
# Folgenden Inhalt mittels vim oder nano einfügen:
events {}
http {
server {
listen 80;
location / {
proxy_pass http://1.2.3.4/;
}
}
}Die obige Konfiguration stellt das absolute Minimum für einen Nginx-Reverse-Proxy dar. Noch dazu wird ausschließlich auf Port 80 gelauscht und damit lediglich HTTP-Traffic verarbeitet. All diese Informationen kann man der listen Direktive entnehmen. Location hingegen gibt an, welchen Pfad der Client übermitteln muss, damit der Reverse-Proxy die Anfrage beachtet.
In diesem simplen Beispiel wird der gesamte eingehende Verkehr verarbeitet, da im Server-Block keine explizite Domain angegeben wurde. Natürlich kann man bei der location auch einen Pfad wie /app1 hinterlegen. Zu guter Letzt wäre noch die Bedeutung der proxy_pass Direktive zu klären. Hier können einfach alle vorhandenen Webserver eingetragen werden.
Bei Docker-Containern würde man beispielsweise noch den Port angeben, auf dem der jeweilige Container lauscht. Neben einer IP-Adresse kann natürlich auch ein vollständiger Domain-Name (FQDN) eingetragen werden. Zum Abschluss der Arbeiten solltest du noch einen DNS-Eintrag erstellen, der auf den Reverse-Proxy verweist. Andernfalls wirst du keine Verbindung aufbauen können.
Noch tut sich aber nichts, wenn ein Client den Nginx-Reverse-Proxy anfragt. Die Konfiguration muss nämlich erst noch aktiviert werden. Dafür genügt es, wenn man unter RedHat die Konfig prüft und dann den Nginx neu startet:
# Konfiguration prüfen:
nginx -t
# Service neu starten:
systemctl restart nginxBei Debian muss man hingegen noch einen Symlink erstellen:
ln -s /etc/nginx/sites-available/reverse-proxy.conf /etc/nginx/sites-enabled/reverse-proxy.confDamit wird ein Softlink erstellt, der im Verzeichnis sites-enabled auf die Konfiguration unter sites-available verweist. Das hat 2 Vorteile: Einerseits muss man bei einer Konfigurationsänderung nur eine Datei bearbeiten und andererseits braucht man die fertige Konfiguration nicht nach sites-enabled zu kopieren. Ansonsten kann genau wie weiter vorne beschrieben vorgegangen werden.
Fortgeschrittene Konfigurationsmöglichkeiten:
In der Praxis wird man die oben vorgestellte Konfiguration niemals finden. Weder würden HTTPS-Anfragen beantwortet werden, noch wäre ein Caching oder zumindest ein Loadbalancing eingerichtet. Wie man so etwas bei einem Nginx-Reverse-Proxy genau umsetzt, werde ich dir im Folgenden aufzeigen. Beginnen wir aber mit der obligatorischen TLS-Terminierung.
SSL-Konfiguration durchführen:
Der aktuell konfigurierte Nginx-Reverse-Proxy würde derzeit noch nicht auf HTTPS-Anfragen reagieren. Das lässt sich aber zum Glück schnell beheben. Man muss lediglich Port 443 zur Listen-Direktive hinzufügen, samt der Pfadangabe zum Zertifikat und dessen privaten Schlüssel.
events {}
http {
server {
listen 80;
listen 443 ssl;
server_name beispiel.de;
ssl_certificate /Pfad/zum/Zertifikat.pem;
ssl_certificate_key /Pfad/zum/Schlüssel.pem;
location / {
proxy_pass http://1.2.3.4:8080/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
}Allerdings ist dies längst nicht alles, was ich an der Konfiguration geändert habe. Nun werden nämlich noch 2 spezielle HTTP-Header verwendet. Diese sind elementar wichtig und daher in vielen Konfigurationen zu verwenden:
- proxy_set_header Host $host; Der $host-Variablenwert wird standardmäßig auf den vollständigen Domainnamen der ursprünglichen Anfrage gesetzt. Das ist gerade dann erforderlich, wenn auf dem Zielserver mehrere Websites gehostet werden. Nur so kann nämlich der Inhalt aus dem korrekten Document-Root ausgespielt werden.
- proxy_set_header X-Real-IP $remote_addr; Der Loadbalancer schickt hier im HTTP-Header die IP-Adresse des Clients mit. Die Backend-Server können also auf diese IP zugreifen, als gebe es gar keinen Reverse-Proxy inmitten des Kommunikationswegs. Manche Webanwendung sind drauf zwingend angewiesen, zum Beispiel wegen Zugriffskontrollen.
Lastverteilung nutzen:
Die Verteilung von Traffic auf Webserver ist eines der Hauptfeatures von Reverse-Proxys. Im folgenden Code-Beispiel werden alle eingehenden Anfrage für die Domain beispiel.de auf die 3 vorhandene Upstream-Server verteilt. Sollte einer von diesen ausfallen, sei es durch einen klassischen Hardwaredefekt oder gar ein Softwareproblem, wird das durch einen Healtheck erkannt.
Im Abstand von 30 Sekunden wird die Unterseite /health_check aufgerufen. Funktioniert das 3-mal hintereinander nicht, wird der betroffene Server nicht mehr kontaktiert. Diese Checks können beim Nginx Plus sehr granular eingerichtet werden. Die folgende Konfiguration prüft den HTTP-Rückgabewert auf den Status 200, was soviel wie okay bedeutet.
events {}
http {
upstream app_servers {
server 10.0.0.1;
server 10.0.0.2;
server 10.0.0.3;
# Check, ob jeder Backend-Server funktioniert:
health_check uri=/health_check;
interval=30s;
fails=3;
}
server {
listen 80;
server_name beispiel.de;
location / {
proxy_pass http://app_servers;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
}Natürlich kann der obige Code wieder um HTTPS-Traffic samt SSL-Terminierung erweitert werden. Ebenso können verschiedene Algorithmen zur Lastverteilung eingesetzt werden. Man hat dabei die Wahl zwischen 5 Methoden:
Round Robin – Gleichmäßige Verteilung:
Dies ist der Standardalgorithmus von Nginx. Bei diesem Algorithmus werden Anfragen nacheinander an die Backend-Server weitergeleitet. Die gerade vorgestellte Konfiguration arbeitet zum Beispiel genau nach diesem simplen Muster.
upstream backend_servers {
server webserver1.beispiel.de;
server webserver2.beispiel.de;
}Least Connections – Die Auslastung zählt:
Bei diesem Algorithmus wird die Anfrage an den Server weitergeleitet, der die geringste Anzahl aktiver Verbindungen hat. Dies ist nützlich, um die Last gleichmäßiger zu verteilen, wenn die Backend-Server unterschiedliche Auslastungen haben.
upstream backend_servers {
least_conn;
server webserver1.beispiel.de;
server webserver2.beispiel.de;
}IP Hash – Kontinuität ist Trumpf :
Mit diesem Algorithmus wird die Verteilung basierend auf der Client-IP-Adresse durchgeführt. Dies stellt sicher, dass Anfragen von denselben Clients immer zum selben Backend-Server weitergeleitet werden. Dies kann bei einer Sitzungsverwaltung oder Caching nützlich sein.
upstream backend_servers {
hash $request_uri consistent;
server webserver1.beispiel.de;
server webserver2.beispiel.de;
}Weighted Load Balancing – Nutze deine Ressourcen optimal:
Du kannst auch Gewichtungen für Backend-Server festlegen, um die Lastverteilung basierend auf der Leistungsfähigkeit deiner Server anzupassen. Dies ist nützlich, wenn einige um ein Vielfaches besser ausgestattet sind als andere.
upstream backend_servers {
server server1.beispiel.de weight=3;
server server2.beispiel.de;
}Random – Der Zufall tut es oft auch:
Dieser Algorithmus der Plus-Version wählt zufällig einen Backend-Server aus.
upstream backend_servers {
random least_time=last_byte;
server webserver1.beispiel.de;
server webserver2.bespiel.de;
}Least Time – Die Latenz zählt:
Diese Lastverteilungsstrategie ist leider nur innerhalb der Plus-Version verfügbar und zielt darauf ab, den Backend-Server mit der geringsten durchschnittlichen Latenz und der niedrigsten Anzahl aktiver Verbindungen zu ermitteln.
upstream backend_server {
least_time header;
server webserver1.beispiel.de;
server webserver2.beispiel.de;
}Je nach den Anforderungen deiner Anwendung und der vorhandenen Serverinfrastruktur, musst du den am besten geeigneten Lastverteilungsalgorithmus auswählen. Es ist dabei nicht selten sinnvoll, Tests durchzuführen und die Leistung unter realen Bedingungen zu überwachen. Nur so lässt sich eine effiziente Lastverteilung ermöglichen.
Performance durch Caching steigern:
Du hast vielleicht schon mal davon gelesen, dass Nginx der schnellste Webserver der Welt ist. Gerade bei statischen Inhalten gilt dies ganz besonders. Wenn du an deinem Reverse-Proxy ein Caching einrichtest, verbesserst du die Leistung deiner Web-Applikation und reduzierst die Last auf deinen Backend-Servern. Wie man so etwas umsetzen kann, soll dieser Beispielcode verdeutlichen:
events {}
http {
proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=static_cache:10m inactive=60m;
proxy_cache_key "$scheme$request_method$host$request_uri";
proxy_cache_valid 200 60m;
server {
listen 80;
server_name example.com;
location / {
proxy_cache static_cache;
proxy_cache_bypass $http_pragma;
proxy_cache_revalidate on;
proxy_pass http://localhost:8080;
}
}
}Proxy-cache_path – Wo der Cache sich versteckt:
Diese Zeile definiert den Speicherort und die Konfiguration für den Cache. Hier wird der Cache-Pfad auf /var/cache/nginx festgelegt, und die Direktie levels gibt die gewünschten Verzeichnisebenen im Cache-Verzeichnis an. 1:2 bedeutet dabei, dass es eine obere Ebene und zwei untergeordnete Ebenen gibt.
Keys_zone – Lass den Cache nicht unendlich groß werden:
Die Eigenschaft key_zone legt den Namen und die Größe des Caches fest. In diesem Fall also einen statischen Cache mit einer Größe von 10 MB. Und wie der Name es schon vermuten lässt, legt das Wörtchen inactive fest, ab wann die Cache-Inhalte als inaktiv gelten und entfernt werden können.
Proxy_cache_key – Klare Identifikation ist angesagt:
Hier wird der Schlüssel für den Cache definiert, der verwendet wird, um die eindeutige Identifikation der gecachten Inhalte sicherzustellen. Der Wert „$scheme$request_method$host$request_uri“ ist eine Kombination aus verschiedenen Komponenten der HTTP-Anfrage.
Genutzt werden also das Schema (http/https), der Anfrage-Methode (GET, POST, usw.), der Hostname und die angeforderte URI. Dies stellt sicher, dass für verschiedene Anfragen unterschiedliche Cache-Schlüssel erstellt werden, um die Inhalte korrekt zuordnen zu können.
Proxy_cache_valid – Lass den Cahe nicht unnötig altern:
Diese Zeile legt fest, wie lange gecachte Inhalte als gültig betrachtet werden. Hier werden nur HTTP-Statuscodes 200 (OK) und die Cache-Zeitspanne von 60 Minuten als gültig angegeben. Dies bedeutet, dass Inhalte mit einem anderen Statuscode nicht gecacht werden und dass gecachte Inhalte nach 60 Minuten als ungültig gelten und erneut vom Backend-Server abgerufen werden müssen.
Location – Wo die Magie beginnt:
In diesem Block wird die Konfiguration für die Verarbeitung von Anfragen getätigt sowie der Caching-Mechanismus aktiviert. Was die einzelnen Direktiven genau bedeuten, erkläre ich dir in den folgenden Zeilen:
- proxy_cache: Diese Zeile gibt an, dass der Cache mit dem Namen static_cache verwendet werden soll. Dies ist der Cache, der zuvor mit proxy_cache_path und keys_zone konfiguriert wurde.
- proxy_cache_bypass: Mit dieser Zeile wird festgelegt, dass der Cache umgangen wird, wenn der Request-Header „Pragma“ gesetzt ist. Dies ermöglicht es, bestimmte Anfragen vom Caching auszuschließen, wenn z. B. ein spezieller Header in der HTTP-Anfrage vorhanden ist.
- proxy_cache_revalidate: Diese Zeile aktiviert die Cache-Revalidierung. Eine wichtige Funktion, da Nginx den Cache-Inhalt erneut überprüft, bevor er an den Client gesendet wird. Es wird also eine Anfrage an den Backend-Server geschickt, wo gefragt wird, ob der Inhalt noch aktuell ist.
Häufig Fragen & meine Antworten:

Reverse-Proxys sind nicht mehr wegzudenken aus der modernen IT-Infrastruktur. Immer wieder erhalte ich daher interessante Leserfragen zu diesem Artikel. Damit auch du von meinen gegebenen Antworten profitieren kannst, habe ich diesen Beitrag noch um einen umfangreichen Frageantwortbereich erweitert:
Ja, dies ist ohne großen Aufwand möglich. Du musst dir also kein eigenes Image bauen und dich mit Dingen wie einem Dockerfile herumschlagen. Es genügt vollkommen, einen Nginx-Container zu starten. Lediglich eine Sache darfst du dabei nicht vergessen, und zwar das Mappen der Konfiguration in den laufenden Container. Das klappt sowohl bei Docker als auch Kubernetes.
Es gibt mehrere Ausweichlösungen zum Nginx, abhängig von deinen spezifischen Anforderungen und Präferenzen. Welche das genau sind und wo sie ihre Stärken haben, verrate ich dir gerne. Das sind die gängigen Lösungen:
Apache HTTP Server (mod_proxy): Apache kann auch als Reverse-Proxy-Server verwendet werden, indem das Modul mod_proxy aktiviert wird. Es bietet ähnliche Funktionen wie Nginx und ist besonders dann nützlich, wenn du bereits mit Apache vertraut bist.
HAProxy: Bewährt hat sich dieser leistungsfähiger TCP/HTTP-Lastenausgleichs-Proxy. Er ist auf die Lastenverteilung und Hochverfügbarkeit spezialisiert und eignet sich gut für komplexe Lastenverteilungsszenarien.
Caddy: Hierbei handelt es sich um einen modernen, einfach zu konfigurierender Webserver und Reverse-Proxy. Er zeichnet sich durch eine automatische HTTPS-Integration und eine benutzerfreundliche Konfiguration aus.
Traefik: Unter DevOpsern ist Traefik sehr beliebt. Bei der Lösung handelt es sich um einen containerisierten Reverse-Proxy samt Lastenausgleichs-Tool. Ausrollen lässt sich Traefik auf Container-Orchestrierungsplattformen wie Docker und Kubernetes.
Squid: Diese Lösung gitl als leistungsstarker Proxy-Server und Webcache. Squid kann als Reverse-Proxy verwendet werden, um Webinhalte zu cachen und zu beschleunigen.
Envoy: Envoy ist ein Edge- und Service-Proxy, der für die Cloud-native Umgebung entwickelt wurde. Er eignet sich besonders gut für Microservices-Architekturen und bietet fortschrittliche Routing- und Lastenausgleichsfunktionen.
Netscaler: Citrix Netscaler ist eine kommerzielle Lösung für Load Balancing und Application Delivery. Er bietet erweiterte Funktionen für Traffic Management und Sicherheit. Leider handelt es sich hier um eine kostenpflichtige Enterprise-Lösung, die sich an Systemhäuser richtet.
Aufgrund von unterschiedlichen Anforderungen und Deployment-Szenarien möchte ich keinen Sieger küren. Es ist viel eher ratsam, die Eigenschaften und Funktionen jeder einzelnen Option zu bewerten und diejenige auszuwählen, die am besten zu deinem Projekt passt. Wer aber einfache Lösung auf Basis des Nginx sucht und gerne mit Docker arbeitet, sollte sich den Nginx-Proxy-Manager näher ansehen. Hier lässt sich alles in der GUI konfigurieren.
Ich selbst nutze hierfür Keepalived. Das Open-Source-Tool ermöglicht die gemeinsame Nutzung einer virtuellen IP-Adresse (VIP) zwischen mehreren Proxys und sorgt so dafür, dass nur ein Server zu einem bestimmten Zeitpunkt den Datenverkehr für diese VIP bearbeitet. Wenn dieser ausfällt, wird der Datenverkehr automatisch vom sekundären Reverse-Proxy bearbeitet.
Keepalived bringt viele nützliche Funktionen mit, wie zum Beispiel die Überwachung des Nginx-Prozesses samt E-Mail-Alarmierung, wenn der primäre Reverse-Proxy ausfällt. Die Konfiguration geht schnell von der Hand und die Lösung funktioniert bereits mit 2 Servern. Andere Möglichkeiten wie Pacemaker oder das RedHat High Availability Add-on benötigen 3 Server wegen des verwendeten Quorum-Mechanismus.