In der Welt der Netzwerkinfrastruktur spielt der Loadbalancer eine entscheidende Rolle. Er ist dafür zuständig, Zuverlässigkeit, Skalierbarkeit und die schnelle Bereitstellung von Online-Diensten sicherzustellen. Eine der am häufigsten verwendeten Lösungen für das Loadbalancing ist Nginx. Das leistungsstarke Open-Source-Tool kann dabei sowohl TCP- als auch UDP-Verbindungen handeln.
In den folgenden Zeilen werde ich detailliert auf das Aufsetzen eines Layer 4 Loadbalancers eingehen. Wer hingegen auf Layer 7 arbeiten möchte, also anhand von Domainnamen Traffic auf bestimmte Webserver verteilen möchte, ist bei diesem Beitrag von mir besser aufgehoben. Dort gehe ich intensiv auf die Thematik Reverse-Proxy mit Nginx ein.
Dieser Artikel hingegen wird dir näher bringen, wie du mit einem Layer 4 Loadbalancer die Performance und Zuverlässigkeit deiner Webanwendung steigerst. Allerdings kannst du das Setup auch nutzen, um DNS-Anfragen auf mehrere Nameserver zu verteilen. Darüber hinaus profitieren natürlich auch Datenbank-Cluster oder Mail-Server vom Vorschalten eines Nginx Loadbalancers.
Das Wesentliche kompakt:
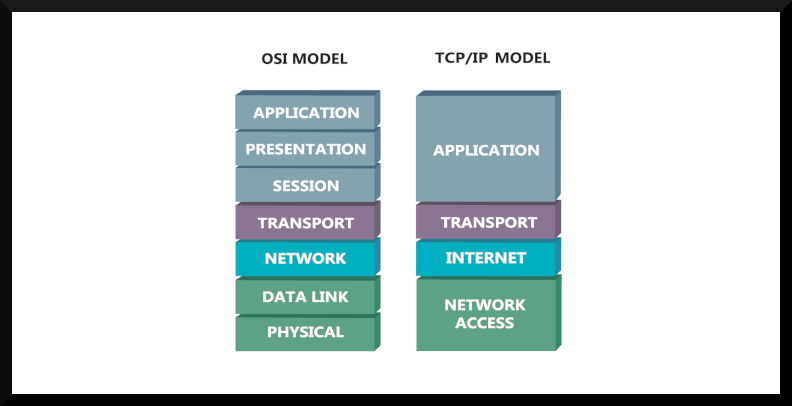
Etwas Theorie muss leider immer sein bei IT-Themen. Loadbalancing über mehrere Anwendungsinstanzen hinweg ist eine häufig verwendete Technik zur Optimierung der Ressourcennutzung, Maximierung der Durchsatzrate, Reduzierung der Latenz und Sicherstellung von ausfallsicheren Setups. Gearbeitet wird dabei entweder auf Layer 4 oder 7 des OSI-Modells.
Layer 4 Loadbalancer:
- Arbeiten auf der Transportebene des OSI-Modells.
- Basiert auf Informationen wie IP-Adressen und Portnummern.
- Verteilen den Datenverkehr auf Basis von Netzwerkpaketen.
- Gut geeignet für TCP/UDP-Loadbalancing und einfache Weiterleitungen.
- Haben begrenzte Einblicke in den Inhalt der Datenpakete.
Layer 7 Loadbalancer:
- Arbeiten auf der Anwendungsebene des OSI-Modells.
- Basiert auf Informationen im HTTP-Header, URL und Inhalt.
- Können intelligente Routing-Entscheidungen basierend auf Anwendungsinhalten treffen.
- Ideal für Anwendungen mit komplexem Routing, SSL/TLS-Terminierung und Inhaltsinspektion.
- Haben detaillierte Einblicke in den Inhalt der Datenpakete.
Layer 4 Loadbalancer sind einfach einzurichten und verteilen Traffic ausgesprochen schnell. Layer 7 Loadbalancer (Reverse-Proxys) sind dafür intelligenter und flexibler in Bezug auf die Verarbeitung von Inhalten. Sie können also smarte Routing-Entscheidungen treffen und zusätzlich mit einer Web-Application-Firewall ausgestattet werden.
Wie man Nginx installiert:
Die Installation von Nginx auf einem Linux-Server ist in der Regel eine einfache Aufgabe. Es spielt dabei keine Rolle, ob du auf Debian oder Red Hat unterwegs bist. Die Paketverwaltungssysteme beider Distributionen bieten passende Pakete an. Alternativ kann man den Nginx selber kompilieren. Das ist hier aber nicht nötig, ermöglicht einem aber zum Beispiel das Hinzufügen bestimmter Module.
Ebenfalls kein Muss, aber durchaus sinnvoll ist die Verwendung der offiziellen Nginx-Repositorys. Diese bieten immer die aktuellsten Updates und Sicherheitspatches an. Durch die Verwendung dieser Repositorys kannst du also sicherstellen, dass deine Nginx-Installation immer auf dem neuesten Stand ist und von den neuesten Funktionen und Verbesserungen profitiert.
Nginx-Installation unter Debian:
Nach der Eingabe des unten befindlichen Installationsbefehls wird das Nginx-Paket aus den Standard-Repositorys heruntergeladen und installiert:
apt update && apt-get install nginx -yNginx-Installation unter RedHat:
Auch unter Rocky Linux oder CentOS findet man in den Paketquellen ein passendes Nginx-Paket. Installiert wird dieses wie folgt:
yum install nginx -yService starten & aktivieren:
Nach Abschluss der Installation kannst du den Nginx-Service starten und in den Autostart legen. Damit ist sichergestellt, dass bei jedem Neustart des Servers automatisch der Nginx gestartet wird:
systemctl enable --now nginxJe nach verwendetem OS ist eventuell eine Firewall auf deinem Server aktiv. Du musst in so einem Fall also noch die passenden Ports und Protokolle freigeben.
Nginx Loadbalancer-Konfiguration:
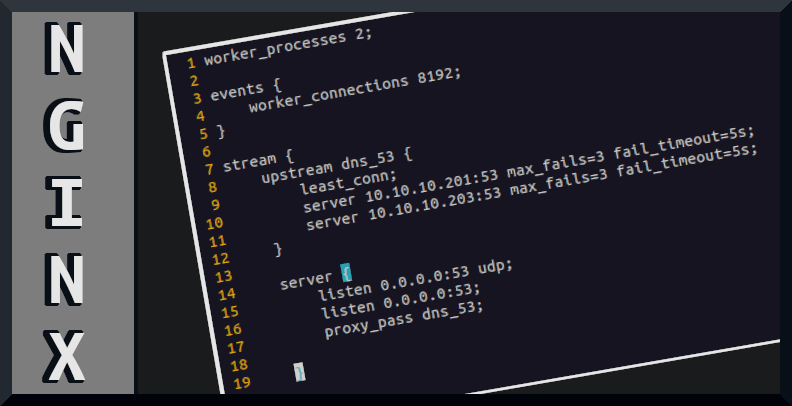
Die Einrichtung eines Nginx Loadbalancers ist nicht besonders komplex. Trotzdem sollte man ein paar Dinge wissen, bevor man irgendeine Konfiguration aus dem Internet kopiert und noch kurz an die eigenen Bedürfnisse anpasst. In der Praxis führt dieses Vorgehen leider häufig dazu, dass der Nginx mit nur einem einzigen Worker-Prozess auskommen muss.
Das bedeutet, dass nur einer der verfügbaren CPU-Kerne genutzt wird. In der Nginx-Konfiguration muss also die Direktive worker_processes auto; hinterlegt werden. Damit ist sichergestellt, dass pro CPU-Kern ein Worker-Prozess gestartet wird. Die Leistung von Nginx steigt damit bereits um ein Vielfaches an. Ebenfalls noch interessant ist der Befehl nginx -t. Damit prüft man seine Konfiguration.
Traffic-Verteilung auf Backend-Server:
Ein gängiges Szenario in der Informatik ist die Streuung von HTTP-Verkehr auf zwei oder mehr Backend-Server. Häufig findet man solche Loadbalancer-Setups vor Kubernetes-Clustern. Dafür muss man unter /etc/nginx/nginx.conf die Gruppe webserver mit der Upstream-Direktive festlegen. Selbstredend müssen hier die IP-Adressen oder FQDNs der Backend-Server eingetragen werden.
Es handelt sich hier schlicht und ergreifend um deine bereits bestehenden Webserver. Wohin der Traffic geroutet werden soll, ist also schon mal definiert worden. Doch auf welchem Port kommen die zu verteilen Anfragen überhaupt rein? Das bestimmst du mithilfe der Server-Direktive. Ich habe hier die Ports 80 und 443 hinterlegt. Die 4 Nullen geben an, dass keine bestimmte IP spezifiziert ist.
worker_processes auto;
events {}
stream {
upstream webserver {
server backend1.example.com;
server backend2.example.com;
}
server {
listen 0.0.0.0:80;
listen 0.0.0.0:443;
proxy_pass webserver;
}
}Die Wahl der Loadbalacing-Methode:
Die obige Konfiguration ist sehr übersichtlich. Das liegt sicherlich auch daran, dass keine Load-Balancing-Methode angegeben wurde. In so einem Fall wird dann auf Round Robin zurückgegriffen. Hier werden die eingehenden Anfragen immer nacheinander auf die Backend-Server verteilt. Allerdings ließe sich auch eine Gewichtung vornehmen, damit der stärkere Server mehr Requests erhält.
Neben Round Robin unterstützt der kostenlose Nginx noch 3 weitere Loadbalancing-Algorithmen. Wer hingegen über den Luxus der Plus-Lizenz verfügt, kann sogar noch 2 exklusive Methoden nutzen. Welche das sind und worin sich alle Algorithmen unterscheiden, erfährst du gleich. Vorher möchte ich aber noch kurz auf den Punkt Server-Gewichtung eingehen.
upstream webserver {
least_conn;
server webserver1.example.com weight=5;
server webserver2.example.com;
}Diese Angaben machen es möglich, dass bestimmte Servern eine höhere oder niedrigere Priorität zugewiesen wird. Servergewichtungen werden also verwendet, um die Lastverteilung manuell zu steuern. Ein Server mit einer höheren Gewichtung erhält dabei mehr Anfragen als ein Server mit einer niedrigeren Gewichtung. Dies ermöglicht es, die Serverressourcen besser zu nutzen.
Schließlich wird so sichergestellt, dass leistungsstarke Server mehr Traffic verarbeiten, während schwächere Server entlastet werden. Besonders interessant ist die Vergabe von Gewichtungen bei physischen Servern, die bereits maximal ausgestattet sind oder wenn manche Backend-Server über schnellere Datenverbindungen als andere verfügen.
Weiterhin kannst du einen Backup-Server definieren. Dieser erhält allerdings nur Anfragen, wenn bereits alle anderen Backend-Server ausgefallen sind:
upstream webserver {
server webserver1.example.com weight=5;
server webserver2.example.com;
server webserver3.example.com backup;
}In der Praxis handelt es sich hierbei meist um ein System, das sich an einem anderen Standort befindet oder zumindest in einem anderen Brandabschnitt. Die Verwendung eines Backup-Servers ist eine bewährte Methode, um die Verfügbarkeit und Stabilität deiner Anwendung in Extremsituationen sicherzustellen. Ein Muss ist die Definition eines Backup-Systems nicht.
Least Connections:
Eine Anfrage wird an den Server gesendet, der die geringste Anzahl aktiver Verbindungen aufweist, wobei auch die Gewichtung der Server berücksichtigt wird. Dies bedeutet, dass der Load Balancer versucht, die Anfragen so auf die Server zu verteilen, dass derjenige Server ausgewählt wird, der aktuell die wenigsten aktiven Verbindungen hat.
Dabei werden die Gewichtungen der einzelnen Server berücksichtigt, sodass Server mit höheren Gewichtungen bevorzugt werden, wenn sie die gleiche Anzahl aktiver Verbindungen haben. Dieses Verfahren zielt darauf ab, die Last gleichmäßig zu verteilen und die Auslastung der Server zu optimieren.
upstream webserver {
least_conn;
server webserver1.example.com;
server webserver2.example.com;
}IP Hash:
Der anzufragende Server wird anhand der Client-IP-Adresse bestimmt. In diesem Fall werden entweder die ersten drei Oktette der IPv4-Adresse oder die gesamte IPv6-Adresse verwendet, um den Hash-Wert zu berechnen. Diese Methode gewährleistet, dass Anfragen von derselben IP-Adresse immer an denselben Backend-Server geleitet werden.
Eine Ausnahme stellt natürlich der Ausfall dieses Backend-Servers dar. Der Algorithmus IP Hash hilft einem dabei, die Kontinuität und Konsistenz von Sitzungen oder Verbindungen für denselben Client sicherzustellen.
upstream webserver {
ip_hash;
server webserver1.example.com;
server webserver2.example.com;
}Generic Hash:
Die Generic Hash Methode ist eine Art der Lastverteilung in Nginx, bei der der Server, an den eine Anfrage gesendet wird, anhand eines benutzerdefinierten Schlüssels bestimmt wird. Dieser Schlüssel kann aus einem Textstring, einer Variablen oder einer Kombination davon bestehen. Mit dieser Methode kannst du den Lastverteilungsschlüssel nach deinen eigenen Anforderungen zu definieren.
Zum Beispiel könnte der Schlüssel aus einem Paar von Quell-IP-Adresse und Port bestehen, oder er könnte eine URI (Uniform Resource Identifier) sein, wie es in der unteren Konfiguration der Fall ist. Die Verwendung eines benutzerdefinierten Schlüssels ermöglicht dir, die Lastverteilung basierend auf bestimmten Kriterien granular zu steuern.
Du könntest beispielsweise Anfragen von verschiedenen Quell-IP-Adressen oder mit unterschiedlichen URIs an verschiedene Server leiten. Dies kann nützlich sein, wenn du spezifische Routing-Anforderungen hast oder wenn du bestimmte Arten von Anfragen auf dedizierte Server verteilen möchtest. Die Generic Hash Methode ermöglicht eine präzise Steuerung über die Verteilung des Datenverkehrs.
upstream webserver {
hash $request_uri consistent;
server webserver1.example.com;
server webserver2.example.com;
}Der Parameter consistent in der obigen hash-Direktive ermöglicht eine konsistente Hash-Lastverteilung nach dem Ketama-Algorithmus. Bei dieser Methode werden Anfragen gleichmäßig auf alle Upstream-Server verteilt, basierend auf dem benutzerdefinierten, gehashten Schlüsselwert. Wenn ein Backend-Server zu einer Upstream-Gruppe hinzugefügt oder daraus entfernt wird, werden nur wenige Schlüssel neu zugeordnet.
Dies minimiert Cache-Misses, insbesondere in Fällen, in denen Lastverteilungs-Cache-Server oder andere Anwendungen verwendet werden, die Zustandsinformationen speichern. Der Hauptvorteil besteht darin, dass die meisten Schlüssel bei Änderungen in der Servergruppe beibehalten werden, wodurch die Wahrscheinlichkeit von Cache-Misses oder anderen Unterbrechungen gering ist.
Least Time (Nginx Plus):
Diese Lastverteilungsstrategie ist leider nur innerhalb der Plus-Version verfügbar und zielt darauf ab, den Backend-Server mit der geringsten durchschnittlichen Latenz und der niedrigsten Anzahl aktiver Verbindungen zu ermitteln. Der Algorithmus verwendet dafür Informationen zur Latenz, um den besten Server für die Bearbeitung einer Anfrage zu ermitteln:
- header: Die Zeit, die benötigt wird, um das erste Byte von der Serverantwort zu empfangen. Dieser Wert misst die Latenz ab dem Zeitpunkt, an dem die Anfrage gesendet wird, bis zum Erhalt des ersten Bytes der Antwort.
- last_byte: Die Zeit, die benötigt wird, um die vollständige Antwort vom Server zu empfangen. Dieser Wert erfasst die Gesamtlatenz bis zum Empfang des letzten Bytes der Serverantwort.
- last_byte inflight: Die Zeit, die benötigt wird, um die vollständige Antwort vom Server zu empfangen, wobei unvollständige Anfragen berücksichtigt werden. Dieser Wert ist besonders nützlich, wenn Anfragen in Teilen übertragen werden und der Zeitpunkt des letzten Bytes entscheidend ist.
Die Auswahl des schnellsten Backend-Servers basiert auf einem der oben vorgestellten Latenzparameter, wobei der Server mit der niedrigsten durchschnittlichen Latenz und der geringsten Anzahl aktiver Verbindungen bevorzugt wird. Ziel dieser Methode ist es, die Leistung und Antwortzeit deiner Webanwendung zu optimieren. Meine unten befindliche Beispiel-Konfiguration nutzt dabei den Header zur Latenzermittlung.
upstream webserver {
least_time header;
server webserver1.example.com;
server webserver2.example.com;
}Random (Nginx Plus teilweise nötig):
Die Methode Random sollte in verteilten Umgebungen verwendet werden, wo mehrere Loadbalancer Anfragen an dieselbe Gruppe Backend-Server weiterleiten. In Szenarien, in denen die Loadbalancer nicht das gesamte Anfragevolumen kennen, kann Random hilfreich sein, um den Traffic gleichmäßig auf die Backend-Server zu verteilen.
Ansonsten würde ich zum Einsatz von anderen Algorithmen wie Round Robin, Least Connections und Least Time raten. Diese ermöglichen eine präzisere und kontrolliertere Lastverteilung, da die Loadbalancer in der Lage sind, die aktuelle Auslastung der Backends zu berücksichtigen und die Anfragen entsprechend zu verteilen. Kommen wir aber nun zu meiner Beispiel-Konfiguration:
upstream webserver {
random two least_time=last_byte;
server webserver1.example.com;
server webserver2.example.com;
server webserver3.example.com;
server webserve42.example.com;
}Wenn der optionale Parameter two angegeben ist, wählt NGINX zuerst zufällig zwei Server aus, wobei die Gewichtungen der Server berücksichtigt werden, und wählt dann einen dieser Server unter Verwendung der angegebenen Methode aus. Es stehen dafür verschiedene Auswahlkriterien zur Verfügung:
- least_conn (Least Connections): In diesem Fall wird der Server ausgewählt, der die geringste Anzahl aktiver Verbindungen aufweist. Dies bedeutet, dass der Load Balancer versucht, Anfragen an den Server zu leiten, der zum Zeitpunkt der Auswahl die wenigsten aktiven Verbindungen hat.
- least_time=header (NGINX Plus): Hier wird der Server ausgewählt, bei dem die durchschnittliche Zeit zum Empfang des Antwort-Headers (gemessen durch die Variable $upstream_header_time) am geringsten ist. Diese Methode wählt den Server aus, der tendenziell die schnellsten Header-Antworten liefert.
- least_time=last_byte (NGINX Plus): Diese Methode wählt den Server aus, bei dem die durchschnittliche Zeit zum Empfang der vollständigen Antwort vom Server (gemessen durch die Variable $upstream_response_time) am geringsten ist. Sie berücksichtigt die gesamte Latenz bis zum Erhalt der gesamten Serverantwort.
Ausfälle mit Health-Checks erkennen:
Ohne Healthchecks ergibt der Betrieb von Loadbalancern nur wenig Sinn. Schließlich sind diese Überprüfungen dazu da, um sicherzustellen, dass jeder einzelne Backend-Server voll funktionsfähig ist. Würde man also keine Healthchecks nutzen, käme es immer wieder zu Traffic-Weiterleitungen an tote Systeme. Das wäre ein Super-GAU und diesen gilt es unbedingt zu vermeiden.
Mit Nginx kannst du spezifische Healthcheck-Routinen konfigurieren, um den Zustand deiner Backend-Server in Echtzeit zu überwachen. Wenn ein Server als nicht gesund klassifiziert wird, wird er vorübergehend aus dem Pool der aktiven Server entfernt. Dadurch wird die Hochverfügbarkeit und Zuverlässigkeit deiner Anwendung sichergestellt.
Ein Healthcheck für einen Layer 4 Loadbalancer mit Nginx Plus lässt sich flott einrichten. Du musst dafür nur angeben, wie oft ein Healtcheck fehlschlagen muss, bis das System keine weiteren Anfragen mehr erhält. Gemacht wird dies mithilfe der Direktive fall=3. Natürlich soll ein deaktivierter Backend-Server erneut genutzt werden, sobald er wieder korrekt funktioniert.
worker_processes auto;
events {}
stream {
upstream webserver {
server webserver1.example.com;
server webserver2.example.com;
}
server {
listen 80;
proxy_pass webserver;
health_check interval=5 rise=3 fall=3 timeout=2;
max_conns 1;
slow_start 30s;
}
}Hier kommt dann die health_check-Direktive ins Spiel. Sie übernimmt unter anderem die Deaktivierung sowie Reaktivierung von Servern basierend auf den Healthcheck-Ergebnissen. Die obigen Parameter geben dabei an, dass die Gesundheitschecks alle 5 Sekunden durchgeführt werden. Es müssen 3 aufeinanderfolgende Checks bestanden werden, damit ein Server als gesund gilt.
Sobald ein Check 3-mal hintereinander nicht bestanden wird, wird der Server aus dem Pool entfernt. Der Timout für die Gesundheitsprüfung beträgt dabei 2 Sekunden. Wird das Zeitlimit überschritten, gilt der Test ebenfalls als nicht bestanden. Die Anweisung max_conns 1 legt fest, dass zu einem kranken Server nur eine einzige Verbindung aufgebaut wird.
Nach einer erfolgreichen Gesundheitsüberprüfung wird die Anzahl der Verbindungen in einem Zeitraum von 30 Sekunden Stück für Stück erhöht. So gibt es zumindest die Direktive slow_start 30s vor. Zu Bedenken ist bei solchen Healthcheck allerdings, dass lediglich die erfolgreiche Verbindung zu Port 80 als Kriterium herangezogen wird. Ob die Webserver antworten, wird nicht geprüft.
Die Überprüfung einer URI lässt sich in Nginx Plus auch implementieren:
worker_processes auto;
events {}
stream {
upstream webserver {
server webserver1.example.com;
server webserver2.example.com;
health_check uri=/health_check;
interval=5s;
fails=3;
}
server {
listen 80;
proxy_pass webserver;
}
}In der obigen Nginx-Konfiguration wird ein benutzerdefinierter Healthcheck durchgeführt, um sicherzustellen, dass die Backend-Server ordnungsgemäß Inhalte ausliefern. Der Check überprüft, ob die URI /health_check auf jedem der Backend-Server erreichbar ist.
- health_check uri=/health_check: Dies ist die Konfiguration für den eigentlichen Healthcheck. Hier wird eine HTTP-Anfrage an die URI /health_check auf jedem der Backend-Server übermittelt.
- interval=30s: Alle 5 Sekunden wird Nginx eine Anfrage an /health_check auf jedem Server senden, um die Gesundheit zu überprüfen.
- fails=3: Dies bedeutet, dass ein Server als krank betrachtet wird, wenn 3 aufeinanderfolgende Healthchecks fehlschlagen.
Zusammengefasst dient dieser Block dazu, einen einfachen Healthcheck zu definieren, der GET-Anfragen an die URI /health_check sendet und den HTTP-Statuscode 200 erwartet. Ist dies 3-mal nicht der Fall, wird der Backend-Server als krank betrachtet. Die Anfragen werden dabei alle 5 Sekunden versendet. Die bis jetzt vorgestellten Konfigurationen funktionieren leider nur bei der Plus-Version.
Der Standard-User hingegen muss sich mit weit weniger Parametern zufriedengeben. So kann man lediglich festlegen, ab wie vielen gescheiterten Gesundheitschecks ein Server als krank gilt und nach welcher Zeitspanne ein Backend-Server wieder automatisch in den Pool aufgenommen wird. Der Timeout greift natürlich auch, wenn ein Server noch immer funktionsuntüchtig ist.
worker_processes auto;
events {}
stream {
upstream webserver {
server webserver1.example.com max_fails=3 fail_timeout=60s;
server webserver2.example.com max_fails=3 fail_timeout=60s;
}
server {
listen 80;
proxy_pass webserver;
}
}HA Nginx-Loadbalancer:

Wer das nötige Kleingeld für die Plus-Lizenz besitzt, braucht sich in puncto Hochverfügbarkeit keine allzu großen Gedanken zu machen. Diese ist nämlich schon integriert und leicht zu aktivieren. Alle anderen müssen hingegen den Umweg über Keepalived gehen. Hierbei handelt es sich um eine simple HA-Lösung auf Basis des Virtual Router Redundancy Protocol.
Mit einfacheren Worten ausgedrückt, lässt sich Keepalived bereits mit 2 Servern in Betrieb nehmen. Die Funktionsweise ist recht primitiv. Es existiert eine virtuelle IP-Adresse (VIP), die bei einem Ausfall vom Primary zum Secondary Node transferiert wird. Standardmäßig wird hier die Netzwerkverbindung zwischen den beiden Knoten überwacht. Allerdings lassen sich auch eigene Skripte integrieren.
Und das ist auch die Art und Weise, wie ich Keepalived in Kombination mit Nginx nutze. Schließlich soll ein Failover ebenso ausgelöst werden, wenn der Nginx-Prozess auf dem Master stirbt. Die Installation und Konfiguration von Keepalived bedarf nur wenig Zeit und Aufwand. Installiert wird sowohl unter Debian als auch RedHat das gleichnamige Paket keepalived.
# RedHat:
dnf install keepalived -y
# Debian:
apt-get install keepalived -yDirekt im Anschluss an die geglückte Installation kann man auch schon die Keepalived-Konfiguration auf beiden Systemen anpassen. Angedacht ist hierbei ein Setup bestehend aus einem Primay (Master) sowie einem Secondary (Backup).
# Konfiguration von Keepalived:
vi /etc/keepalived/keepalived.conf
# Konfiguration für den Primary-Loadbalancer:
! Configuration File for keepalivedglobal_defs {
...
}vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
interval 2
weight 50
}vrrp_instance VI_1 {
state MASTER
interface ens18 # Bitte noch anpassen
virtual_router_id 50
priority 110
advert_int 1
virtual_ipaddress {
1.3.5.7/24
}
track_script {
check_nginx
}
}
# Konfiguration für den Secondary-Loadbalancer:
! Configuration File for keepalivedglobal_defs {
...
}vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
interval 2
weight 50
}vrrp_instance VI_1 {
state BACKUP
interface ens18 # Bitte noch anpassen
virtual_router_id 50
priority 100
advert_int 1
virtual_ipaddress {
1.3.5.7/24
}
track_script {
check_nginx
}
}Bereits zum jetzigen Zeitpunkt hat man eine einfache HA-Lösung am Laufen, die zumindest Netzwerkprobleme abfängt. Allerdings wäre es noch sinnvoll von Zeit zu Zeit zu schauen, ob auf dem Master der Nginx-Loadbalancer läuft. Dafür erstellt man einfach ein kleines Skript, welche genau diese Aufgabe übernimmt:
# Pfad für das Skript:
vi /etc/keepalived/check_nginx.sh
#!/bin/sh
if [ -z "`/bin/pidof nginx`" ]; then
systemctl stop keepalived.service
exit 1
fi
# Das Skript ausführbar machen:
chmod +x /etc/keepalived/check_nginx.shUnd zum Abschluss der Arbeiten muss Keepalived natürlich noch gestartet werden und in den Autostart gepackt werden. Dies gelingt dir mit folgendem Befehl:
systemctl enable --now keepalived Die Keepalived-Konfiguration in diesem Artikel ist bewusst sehr einfach gehalten. Du kannst allerdings noch eine Sektion hinzufügen, wo du bei einem Schwenk des Masters per E-Mail benachrichtigt wirst. Dafür brauchst du allerdings einen funktionierenden Mail-Transfer-Agenten (MTA) in deinem Netzwerk.